GATKの導入-GATK解説シリーズ-part 1
GATKの導入とPATHの通し方
今回は何をする?
- GATK4を自分のPCに導入します。
GATKとは
GATKはBroad研究所が提供する、変異の検出に特化したゲノム解析ツールキットです。非常に多機能でゲノム解析分野で業界標準として広く使われていますが、操作難易度が高く、初心者は必ず躓くポイントになっています。GATKはもともとヒトゲノム解析用に開発されたものですが、現在ではあらゆる生物のゲノムデータを扱えるように進化しています。その範囲は、体細胞・生殖細胞のショートバリアント/インデル検出、コピー数(CNV)や構造変異(SV)への解析に及びます。また、GATKには、WGSの処理や品質管理などの関連作業を行うための多くのユーティリティが含まれており、頻繁に使われるPicardも搭載されています。また、GATKの読み方は(ジー・エー・ティー・ケイ)です。公式HPはこちら
また、本記事の内容はGetting started with GATK4の1-6に該当します。
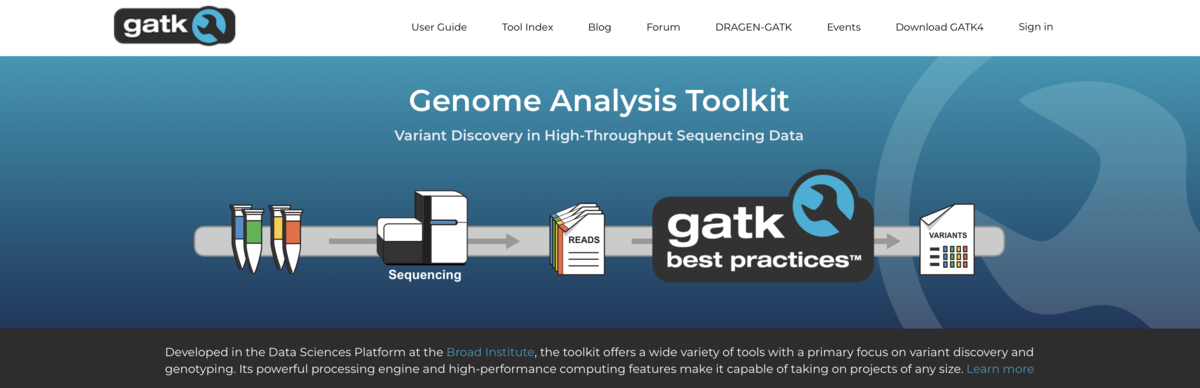
GATK Best Practiceとは (GATK公式HPより引用・翻訳)
研究室でDNAを分離するとき、その作業を孤立したバラバラの作業のようには扱いません。すべての作業は、規定されたプロトコルのステップであり、収量と純度を最適化し、再現性とすべてのサンプルと実験における一貫性を確保するために慎重に取り扱われます。GATKは、シーケンシングデータの処理も同じように徹底的に行われるべきだという開発者らの理念に基づき、一連の作業を網羅したベストプラクティスのワークフローの使用が推奨されています。これは、ブロード研究所でテストされ、最も正確な結果を最も高い計算効率で得られるように最適化されています。
GATKを始めるには
GATKはLinuxまたはMacOSXで動作し、Windowsはサポートされていません。 Java 8 / JDK 1.8がインストールされていることを確認してください(OracleまたはOpenJDK、どちらでも構いません)。 GATKのパッケージはこちらから最新版(今回はGATK4.2.0.0)をダウンロードしてください。
ダウンロードしたファイルにインストールは必要ありません。ダウンロードしたパッケージを開き、jarファイルと起動スクリプトの入ったフォルダを、ハードディスクの作業ディレクトリに置くだけ使用することができます。
Twitterで記事の更新をお知らせしているので、興味を持たれた方は是非フォローをお願いします。
フォローする @harrykun_blog
2. 動作確認を行う。
試しに、gatk-4.2.0.0のフォルダを作業ディレクトリに設定して、GATKが認識されているか確認する。
cd /path/to/gatk-4.2.0.0 #ダウンロードしたフォルダのディレクトリへ移動する。 ./gatk --help #Helpを表示する。
ここまでが上手くできていると、下記が表示される。
Usage template for all tools (uses --spark-runner LOCAL when used with a Spark tool)
gatk AnyTool toolArgs
Usage template for Spark tools (will NOT work on non-Spark tools)
gatk SparkTool toolArgs [ -- --spark-runner <LOCAL | SPARK | GCS> sparkArgs ]
Getting help
gatk --list Print the list of available tools
gatk Tool --help Print help on a particular tool
Configuration File Specification
--gatk-config-file PATH/TO/GATK/PROPERTIES/FILE
gatk forwards commands to GATK and adds some sugar for submitting spark jobs
--spark-runner <target> controls how spark tools are run
valid targets are:
LOCAL: run using the in-memory spark runner
SPARK: run using spark-submit on an existing cluster
--spark-master must be specified
--spark-submit-command may be specified to control the Spark submit command
arguments to spark-submit may optionally be specified after --
GCS: run using Google cloud dataproc
commands after the -- will be passed to dataproc
--cluster <your-cluster> must be specified after the --
spark properties and some common spark-submit parameters will be translated
to dataproc equivalents
--dry-run may be specified to output the generated command line without running it
--java-options 'OPTION1[ OPTION2=Y ... ]' optional - pass the given string of options to the
java JVM at runtime.
Java options MUST be passed inside a single string with space-separated values.
--debug-port <number> sets up a Java VM debug agent to listen to debugger connections on a
particular port number. This in turn will add the necessary java VM arguments
so that you don't need to explicitly indicate these using --java-options.
--debug-suspend sets the Java VM debug agent up so that the run get immediatelly suspended
waiting for a debugger to connect. By default the port number is 5005 but
can be customized using --debug-port
jarファイル自体を単純にPATHに追加することはできないが、以下のようにすると追加することができる。
以下に、私の環境(MacOS Big Sur 11.4)でのPATHの通し方を説明する。
2. デフォルトシェルを確認する。
$ echo $SHELL #デフォルトシェルを表示する /bin/bash # bashの場合 /bin/zsh # zshの場合
ブログ主の場合bashをデフォルトにしているのでbashの場合を主に説明する。
3. シェルに応じて設定ファイルを作成する。
まずはhomeディレクトリに移動する。
cd ~
次に、設定ファイルがあるか確認する。
-aは隠しファイルを含め全てのファイルを表示するためのオプション。
ls -a
.zshrc または .bash_profile が存在しなければここで表示されない。
ファイルがない場合は、.bash_profile または.zshrcを作成する。
touch .bash_profile #もしくはtouch .zshrc
4. 設定ファイルにPATHを追記する。
open ~/.bash_profile #もしくはopen ~/.zshrc
テキストエディタが起動する。 設定する下記内容をテキストに追記する。
export PATH="/path/to/gatk-package/:$PATH"
/path/to/gatk-package/はgatk実行ファイルの場所へのパスである。動作させるためには、jarはgatkと同じディレクトリに置かれていなければならないことに注意する。パスには必ず最後の/が必要である。
また、.bash_profile ファイル内でエイリアスを作成し、gatk と入力するだけでファイルパスが実行されるようにすることも可能である。
alias gatk='/path/to/gatk-package/gatk'
ファイルを保存する。 最後に、下記のコードをターミナルに入力し設定した内容を反映させる。
source ~/.bash_profile #もしくはsource ~/.zshrc
5. 最後に、PATHが正しく機能することを確認する。
./gatk --help #aliasを記載した場合は、単にgatk --help
PATHを通す前に実行した時と同じテキストが出力される。
お疲れ様でした。今回はこれで終わりです。 よければ他の記事のも見ていってください。
なお、本記事の執筆にあたり、下記記事[【zsh, bash】macでPATHを通す方法 - not found と出てしまったら]を参考にさせていただきました。 qiita.com
続きは↓こちら
eupatho-bioinfomatics.hatenablog.com
本記事の内容はGetting started with GATK4の1-6に該当します。
[https://gatk.broadinstitute.org/hc/en-us/articles/360036194592-Getting-started-with-GATK4:title]